.png)
Synthetic data vs human feedback: when AI still needs humans
A clear way to when AI models can rely on synthetic data and when human feedback remains essential for alignment, safety, and frontier performance.



.png)
Reinforcement Learning from Human Feedback (RLHF) improves AI by using human input to fine‑tune models, making outputs safer, accurate, and aligned with user needs.
Artificial intelligence models like GPT-3 and GPT-4 have shown remarkable capabilities, but they didn’t get there by just training on massive datasets. These models often produced biased, irrelevant, or even harmful outputs when they were only trained with traditional supervised or unsupervised learning methods. That’s where reinforcement learning with human feedback (RLHF) comes in.
RLHF bridges the gap between raw AI capabilities and outputs that are helpful, safe, and aligned with human expectations. Instead of relying solely on static datasets, RLHF adds a crucial step: humans evaluate and rank AI-generated responses. Their feedback guides the model on what “good” output looks like, improving its reasoning, tone, and factual reliability over time.
This approach has transformed AI alignment. It’s why tools like ChatGPT, Claude, and other advanced models feel more conversational and context-aware today. RLHF essentially puts humans “in the loop,” ensuring that AI systems can learn from nuanced, real-world judgment, something that pure algorithms can’t replicate.
For organizations building AI products, RLHF is more than just a training technique. It’s becoming the gold standard for creating trustworthy AI, especially in sensitive domains like healthcare, finance, and law, where expert-led validation matters far more than generic crowdsourced data.
Reinforcement Learning from Human Feedback (RLHF) is a machine learning technique that combines reinforcement learning with direct human feedback to align AI behavior with real-world expectations. Instead of relying only on static datasets or predefined reward functions, RLHF uses human evaluators to rank and compare model outputs. The process of collecting human feedback involves prompting human annotators to evaluate, rank, or edit the model's outputs, providing valuable data that reflects human preferences. This feedback is used to train a reward model, which then guides the AI agent through reinforcement learning to produce responses that are safer, more accurate, and contextually relevant. Direct feedback from human evaluators, such as scalar ratings or head-to-head comparisons, is used to generate a reward signal for the reward model, a process known as reward modeling.
The motivation for RLHF comes from a key limitation of traditional reinforcement learning: manually designed reward functions often fail to capture subjective human preferences or complex ethical considerations. By integrating human judgment into the training loop, RLHF helps AI systems learn what people actually value, making them more useful in nuanced tasks such as conversational AI, decision-making, and creative content generation. This approach has become essential for building advanced language models like ChatGPT and Claude, as well as AI systems in robotics and gaming that must adapt to human feedback in real-world scenarios. RLHF also enables AI systems to adapt and learn effectively in dynamic environments by incorporating human guidance.
Reinforcement Learning from Human Feedback (RLHF) is a training approach that improves AI alignment by combining reinforcement learning with human judgment. RLHF typically starts with a pre trained model or initial model, which is then fine-tuned using human feedback. Instead of relying solely on static, pre‑defined reward functions, RLHF introduces human evaluators who compare and rank different model outputs generated from the same prompt based on quality, safety, and relevance. The evaluation of the model's outputs helps guide the refinement process. Their preferences are used to train a reward model, which then fine‑tunes the AI agent through reinforcement learning, enabling an iterative learning process. This method, called reinforcement learning from human feedback, addresses a key limitation of traditional training, AI models often lack contextual understanding of what makes an answer useful or ethical. RLHF has become a foundational technique for large language models (LLMs) such as ChatGPT, Claude, and Gemini, helping them generate responses that are more accurate, factual, and aligned with real‑world human expectations.
Beyond natural language processing, RLHF has also been successfully applied to domains like gaming and robotics, showcasing its versatility in improving AI systems across various fields. RLHF plays a crucial role in developing powerful ai systems and generative ai, and is significant in advancing ai development by making AI safer, more scalable, and ethically aligned.
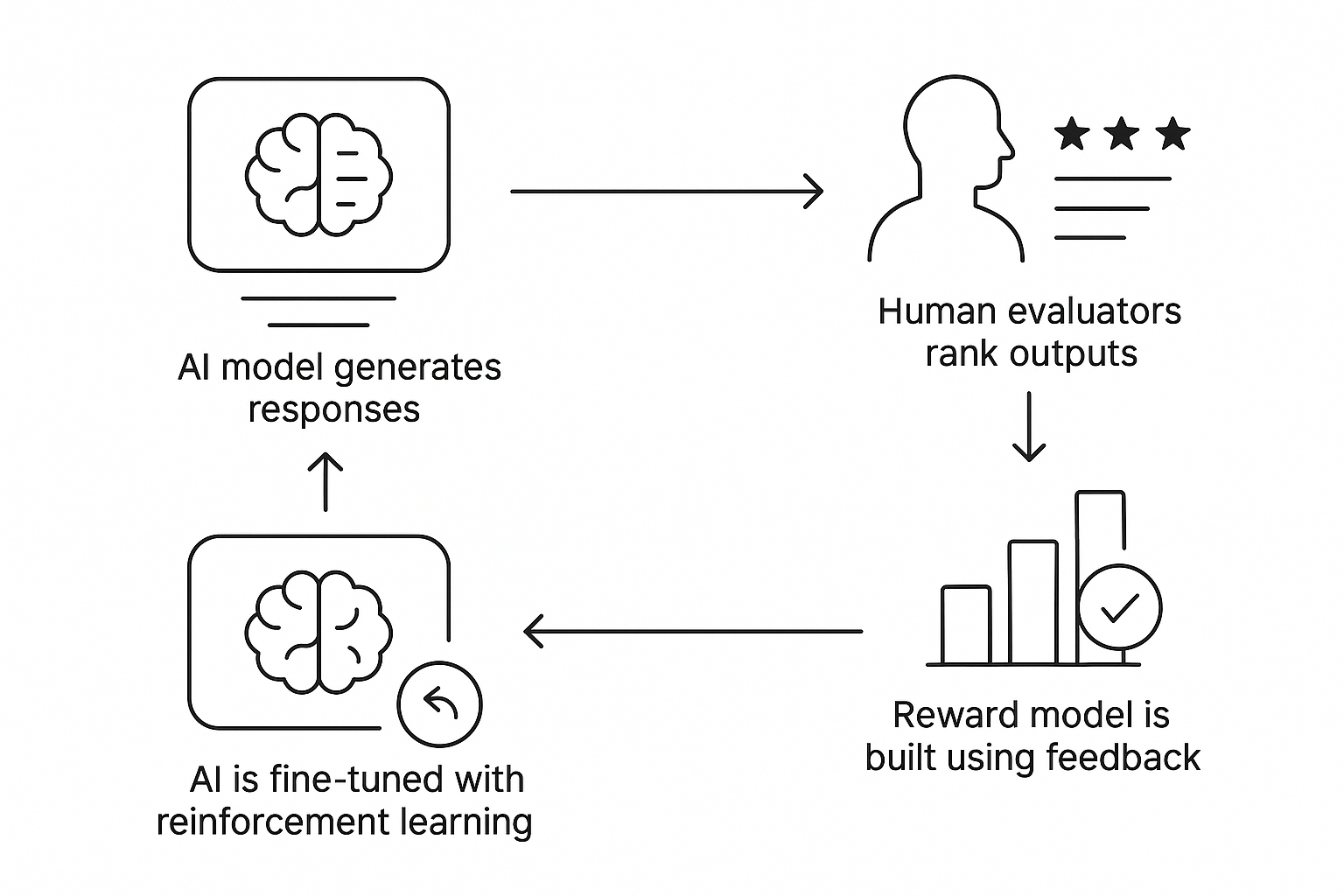
RLHF addresses one of the biggest challenges in AI training: aligning model behavior with human values, context, and intent. In particular, understanding user intent is crucial in RLHF, as it ensures that language models can accurately interpret and respond to what users actually mean, leading to more relevant and effective interactions. Traditional reinforcement learning relies on predefined reward functions, which often fail in complex, ambiguous scenarios. By incorporating human feedback, RLHF enables AI models to:
As AI systems become more integrated into decision-making, RLHF has emerged as a critical step for building models that are not just capable but also responsible and aligned with user needs. RLHF also enhances natural language understanding, allowing models to better grasp, interpret, and respond to user needs across a variety of NLP tasks. Additionally, RLHF improves the model's ability to replicate the nuances of human communication, making AI responses more natural and emotionally intelligent.

Language models are a foundational technology in artificial intelligence, designed to process, understand, and generate human language. By training on massive datasets of text, language models learn the intricate patterns, structures, and relationships that make up natural language. This enables them to perform a wide range of tasks, including text generation, translation, summarization, and sentiment analysis.
Large language models, such as those powering today’s most advanced AI systems, have demonstrated remarkable abilities in generating coherent, contextually relevant, and human-like text. These models can answer complex questions, carry on conversations, and assist with creative writing, making them invaluable tools across industries. However, the training process for large language models is resource-intensive, requiring vast amounts of data and computational power.
To further enhance the quality and safety of language model outputs, incorporating human feedback has become essential. Techniques like reinforcement learning from human feedback (RLHF) allow these models to learn directly from human preferences, ensuring that their responses are not only accurate but also aligned with real-world expectations. By learning from human feedback, language models can better understand context, intent, and subtle nuances, resulting in more reliable and trustworthy AI-powered communication.
Reinforcement Learning from Human Feedback (RLHF) is not just a training method but a bridge between raw AI capability and human expectations. Traditional models learn patterns from vast datasets but often fail to understand what responses humans actually find helpful or safe. RLHF fills this gap by teaching AI to prioritize human‑preferred outputs over purely statistical predictions.
It combines three core elements such as supervised learning, reinforcement learning, and human evaluation in order to create systems that align better with real‑world needs. The RLHF process involves training a language model through a feedback loop, often referred to as a reinforcement learning loop. In this loop, human evaluators assess the model's responses to various prompts, evaluating the quality and alignment of the model's responses with human preferences. The ranking of model responses, using methods like head-to-head comparisons or categorical ratings, is then used to train the reward model. Instead of relying on rigid, pre‑defined reward functions, RLHF incorporates continuous feedback loops from human evaluators, making the AI more adaptive, context‑aware, and trustworthy. This training process is iterative and involves training the model to improve model performance based on human feedback. The reward function translates human preferences into a score that guides the model's learning.
The RLHF training process follows three core stages that turn a pre‑trained language model into a human‑aligned AI assistant:
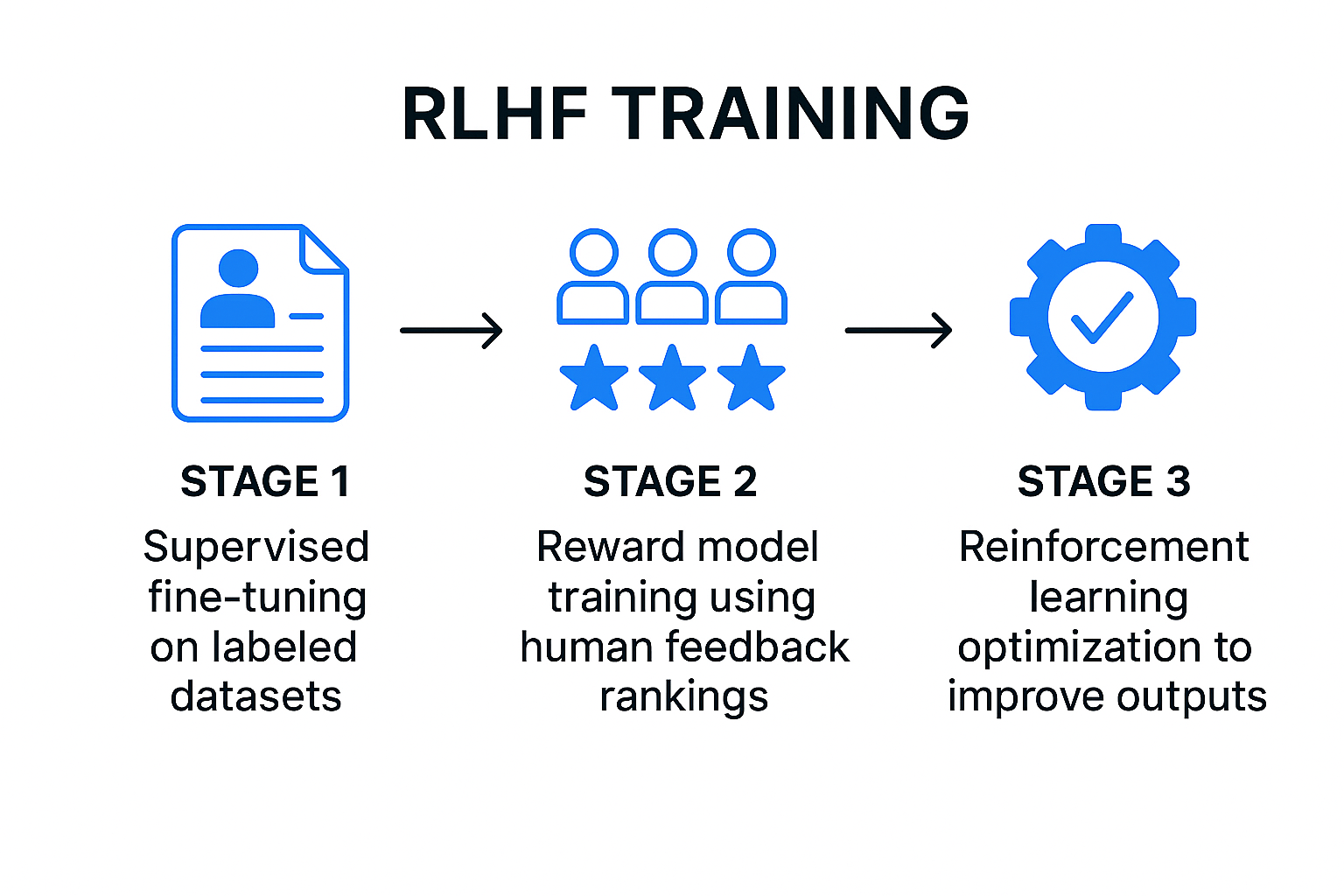
Data generation is a foundational step in the RLHF process, as the quality of human feedback directly influences the effectiveness of the reward model. To collect meaningful human preference data, human annotators evaluate model outputs by ranking, rating, or providing corrections to the AI’s responses. The quality of the training data used to train large language models is fundamental to their ability to generate relevant and accurate responses. This feedback data serves as the basis for training the reward model, which learns to predict which outputs best match human preferences. A preference model can also be trained from human preference data to further refine model outputs based on specific principles or guidelines. The process of data collection is critical, high-quality, diverse feedback ensures that the reward model can generalize well to new situations. Techniques such as data augmentation and active learning are often employed to make data generation more efficient, allowing for the collection of richer and more informative feedback with fewer resources. Ultimately, the success of RLHF depends on the careful design and execution of the data generation process, as it forms the backbone of the system’s ability to learn from human feedback.
Direct Preference Optimization (DPO) is an innovative approach within RLHF that streamlines the process of aligning language models with human preferences. Unlike traditional RLHF methods, which require training a separate reward model to interpret human feedback, DPO leverages preference data directly to fine-tune the language model. This means that instead of building and maintaining a separate reward model, the training process uses human preference data to optimize the model’s responses in a more straightforward and efficient manner.
By applying direct preference optimization, language models can be trained to better reflect what users actually want, resulting in outputs that are more accurate, relevant, and aligned with human values. DPO simplifies the training process, reduces the need for extensive hyperparameter tuning, and accelerates the path from collecting preference data to improving model performance. As a result, DPO is becoming an increasingly popular method for fine-tuning language models to match human preferences, making AI systems more responsive and effective in real-world applications.
RLHF enables AI systems to improve their performance by incorporating human input.
RLHF has unlocked a wide array of applications across different fields, thanks to its ability to align AI behavior with human intent. In natural language processing, RLHF is used to fine-tune large language models, enhancing their performance in text generation, conversational dialogue, and other language-based tasks. This results in language models that produce more relevant, accurate, and context-aware responses. In robotics, RLHF enables robots to learn complex tasks such as navigation, object manipulation, and interaction with humans, all guided by human feedback and human guidance rather than rigid programming. The gaming industry leverages RLHF to create more engaging and realistic game environments, where AI agents can adapt to player preferences and strategies, with human guidance playing a crucial role in training these agents. Beyond these areas, RLHF is also being explored in education and healthcare, where personalized learning systems and adaptive support tools benefit from AI that can learn directly from human input, with human expertise being especially important in providing feedback in sensitive domains like healthcare and law. In the data collection process, human raters are responsible for evaluating and ranking model outputs, providing the feedback necessary for effective training. By enabling AI systems to fine tune their behavior based on human feedback and reward learning as a key process, RLHF is driving innovation in how machines tackle complex tasks across diverse domains.
RLHF is especially valuable for language generation, where it enhances the ability of AI models to generate more coherent, human-aligned responses.
While RLHF has become a leading method for aligning language models with human values, there are several alternative approaches that can achieve similar goals. One notable alternative is Reinforcement Learning from AI Feedback (RLAIF), which replaces human feedback with AI-generated feedback. By using AI feedback, organizations can reduce the time and resources required for collecting human input, making the training process more scalable and efficient. RLAIF can also be used alongside RLHF to further enhance model performance and adaptability.
Another approach is fine-grained RLHF, which involves breaking down human feedback into more detailed and specific components. This method provides the language model with precise guidance, allowing it to better understand and respond to complex or nuanced user preferences. By leveraging both AI feedback and more granular human feedback, these alternatives to RLHF offer flexible strategies for improving language models and ensuring their outputs meet the diverse needs of users.
Reinforcement Learning from Human Feedback is reshaping how AI systems are trained, helping models like ChatGPT and Claude produce outputs that are safer, more factual, and aligned with human expectations. As AI adoption grows across industries, RLHF is becoming essential for organizations that need trustworthy, human-centered AI. By understanding its process, benefits, and challenges, teams can make better decisions about how to implement RLHF in their AI workflows.
Access identity-verified professionals for surveys, interviews, and usability tests. No waiting. No guesswork. Just real B2B insights - fast.
Book a demoJoin paid research studies across product, UX, tech, and marketing. Flexible, remote, and designed for working professionals.
Sign up as an expertInstantly discover and recruit world-class industry experts, C-suite executives and consultants for research.
.png)
.png)